WEEK-6 ( 22/02/2021 - 26/02/2021 )
So week 6 started with new topics of Model Evaluation and Selection.
Model evaluation: It aims at estimating the generalization error of the selected model, i.e., how well the selected model performs on unseen data. Obviously, a good machine learning model is a model that not only performs well on data seen during training (else a machine learning model could simply memorize the training data), but also on unseen data. Hence, before shipping a model to production we should be fairly certain that the model’s performance will not degrade when it is confronted with new data.
Model selection: It is the process of selecting one final machine learning model from among a collection of candidate machine learning models for a training dataset. Model selection is a process that can be applied both across different types of models (e.g. logistic regression, SVM, KNN, etc.) and across models of the same type configured with different model hyperparameters (e.g. different kernels in an SVM).
How to evaluate the ML models?
Models can be evaluated using multiple metrics. However, the right choice of an evaluation metric is crucial and often depends upon the problem that is being solved. A clear understanding of a wide range of metrics can help the evaluator to chance upon an appropriate match of the problem statement and a metric.
Classification metrics
For every classification model prediction, a matrix called the confusion matrix can be constructed which demonstrates the number of test cases correctly and incorrectly classified.
It looks something like this (considering 1 -Positive and 0 -Negative are the target classes):

TN: Number of negative cases correctly classified
TP: Number of positive cases correctly classified
FN: Number of positive cases incorrectly classified as negative
FP: Number of negative cases correctly classified as positive
Accuracy Accuracy is the simplest metric and can be defined as the number of test cases correctly classified divided by the total number of test cases.
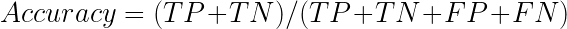 It can be applied to most generic problems but is not very useful when it comes to unbalanced datasets. For instance, if we are detecting frauds in bank data, the ratio of fraud to non-fraud cases can be 1:99. In such cases, if accuracy is used, the model will turn out to be 99% accurate by predicting all test cases as non-fraud. The 99% accurate model will be completely useless. If a model is poorly trained such that it predicts all the 1000 (say) data points as non-frauds, it will be missing out on the 10 fraud data points. If accuracy is measured, it will show that that model correctly predicts 990 data points and thus, it will have an accuracy of (990/1000)*100 = 99%! This is why accuracy is a false indicator of the model’s health.
It can be applied to most generic problems but is not very useful when it comes to unbalanced datasets. For instance, if we are detecting frauds in bank data, the ratio of fraud to non-fraud cases can be 1:99. In such cases, if accuracy is used, the model will turn out to be 99% accurate by predicting all test cases as non-fraud. The 99% accurate model will be completely useless. If a model is poorly trained such that it predicts all the 1000 (say) data points as non-frauds, it will be missing out on the 10 fraud data points. If accuracy is measured, it will show that that model correctly predicts 990 data points and thus, it will have an accuracy of (990/1000)*100 = 99%! This is why accuracy is a false indicator of the model’s health.
Therefore, for such a case, a metric is required that can focus on the ten fraud data points which were completely missed by the model.
Therefore, for such a case, a metric is required that can focus on the ten fraud data points which were completely missed by the model.
Precision: Precision is the metric used to identify the correctness of classification.
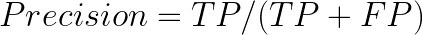
Intuitively, this equation is the ratio of correct positive classifications to the total number of predicted positive classifications. The greater the fraction, the higher is the precision, which means better is the ability of the model to correctly classify the positive class.In the problem of predictive maintenance (where one must predict in advance when a machine needs to be repaired), precision comes into play. The cost of maintenance is usually high and thus, incorrect predictions can lead to a loss for the company. In such cases, the ability of the model to correctly classify the positive class and to lower the number of false positives is paramount!RecallRecall tells us the number of positive cases correctly identified out of the total number of positive cases.
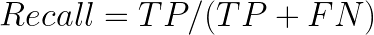 Going back to the fraud problem, the recall value will be very useful in fraud cases because a high recall value will indicate that a lot of fraud cases were identified out of the total number of frauds.
Going back to the fraud problem, the recall value will be very useful in fraud cases because a high recall value will indicate that a lot of fraud cases were identified out of the total number of frauds.
Intuitively, this equation is the ratio of correct positive classifications to the total number of predicted positive classifications. The greater the fraction, the higher is the precision, which means better is the ability of the model to correctly classify the positive class.In the problem of predictive maintenance (where one must predict in advance when a machine needs to be repaired), precision comes into play. The cost of maintenance is usually high and thus, incorrect predictions can lead to a loss for the company. In such cases, the ability of the model to correctly classify the positive class and to lower the number of false positives is paramount!RecallRecall tells us the number of positive cases correctly identified out of the total number of positive cases.
F1 Score: F1 score is the harmonic mean of Recall and Precision and therefore, balances out the strengths of each. It is useful in cases where both recall and precision can be valuable – like in the identification of plane parts that might require repairing. Here, precision will be required to save on the company’s cost (because plane parts are extremely expensive) and recall will be required to ensure that the machinery is stable and not a threat to human lives.
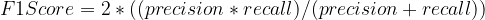

Comments
Post a Comment